
Závislosti mezi tasky
Tasky téměř nikdy nestojí samostatně. To není nic moc překvapivého. Známe to z Antu, známe to z Mavenu, bylo by divný, kdyby to Gradle dělal jinak. Když si například vezmeme klasický Maven build lifecycle, tak vypadá nějak takhle:- zpracuj resources,
- zkompiluj třídy,
- zpracuj test-resources,
- zkompiluj třídy testů,
- spusť testy,
- vytvoř archiv,
- atd.
Tyto jednotlivé úkony (v Mavenu nazývané goals) na sebe logicky navazují a jsou na sobě implicitně závislé. Implicitně znamená, že nemusím závislost jednotlivých tasků (goals) explicitně uvádět - Maven "už to nějak ví", jak si ty tasky má seřadit. Magie? Ne, "někdo" mu to řekl.
Podobné je to i v Gradlu. Některé tasky už mají závislosti definované, většinou je to v rámci nějakého pluginu. Třeba u Java pluginu (o kterém si budeme povídat v příště) vytváří závislosti cyklus, který je velmi podobný tomu Mavenímu. Velkou výhodou Gradlu je, že závislosti mezi tasky se definují velmi jednoduše a navíc nad nimi máme programovou kontrolu.
Závislost tasku se dá definovat buď pomocí property nebo metodydependsOn. Způsob zápisu se může podobat tomu, který známe z Antu, čili přímo při definici tasku:
task first << { task ->Anebo můžeme využít nespoutanosti Groovy a závislost definovat v podstatě na libovolném místě:
println" Working on the ${task.name} task"
}
task second(dependsOn: first) << { task ->
println" Working on the ${task.name} task"
}
task third << { task ->Vzhledem k tomu, že zde máme závislost tasků third -> second -> first, výstup by při spuštění tasku third měl vypadat následovně:
println" Working on the ${task.name} task"
}
third.dependsOn second
 |
| Závislost tasků |
Zajímovou možností je definovat závislosti tasku dynamicky. Vstupem do metody dependsOn totiž může být closure, jedinou podmínkou je, aby vracela objekt typu Task, nebo kolekci Tasků.
task fourth << { task ->V uvedeném výpisu je task fourth závislý na všech tascích projektu, které jsou seskupeny pomocí vlastnosti group.
println" Working on the ${task.name} task"
}
fourth.dependsOn {
tasks.findAll { task -> task.group.equals('sequence') }
}
Zdrojový kód na Bitbucketu: 02_TaskDependencies/build.gradle
Přeskočení tasku
Ať už jste agilní vývojáři, kteří milují dynamické prostředí, nebo jste naopak vyznavači petrifikovaného zadání, jedno je jisté - chtěná, či nechtěná, stejně přijde nějaká změna. A tak, jakkoliv je náš pracovní lifecycle vymazlený, bude do něj potřeba zasáhnout. Někdy třeba jen dočasně.
(Při psaní příkladů pro tuto část jsem měl rozvernou náladu, takže v této sekci bude naším průvodcem jeden z hrdinů mého dětství, klokan Skippy :-)
První ze způsobů, jak přeskočit task, je využití metody onlyIf, pro kterou můžeme definovat predikát. Akce v tasku (a tím pádem i task samotný) jsou vykonány pouze tehdy, pokud je predikát vyhodnocen jako true.
task skippy << {V tomto příkladu je task skippy vykonán pouze tehdy, pokud je projektová property isHappy nastavena na true. Pokud takovou property v build skriptu nemáme definovanou, nevadí - přidáme si ji z příkazové řádky pomocí přepínače -P, např. -PisHappy=true.
println'I\'m happy, so I jump!'
}
skippy.onlyIf { project.isHappy == 'true' }
 |
| Přeskočení tasku pomocí metody onlyIf |
Další možnost, jak nevykonat task, nebo jeho část, je vyhodit výjimku StopExecutionException. To způsobí, že je zastaveno vykonávání aktuálního tasku a je spuštěno vykonání toho následujícího. Tato výjimka přeruší pouze daný task, build pokračuje dál.
task exceptionalSkippy << {Jak je vidět na následujícím výstupu, task exceptionalSkippy nebyl přeškočen (jako v předešlém příkladu), ale byl normálně spuštěn a pak byl někde "uvnitř" přerušen.
if (project.isHappy == 'false') {
thrownewStopExecutionException()
}
println'I\'m happy, so I jump!'
}
 |
| Přerušení tasku pomocí StopExecutionException |
Třetí možností, jak rozhodnout o vykonání tasku je použití property enabled - task tak můžeme vypnout, nebo zapnout.
V následujícím příkladu máme dva tasky. Task disabledSkippy (který nám řekne, jestli Skippy bude skákat) závisí na tasku skippyMood (který nám oznámí Skippyho náladu). Task skippyMood má možnost vypnout task disabledSkippy.
task skippyMood << {
if (project.isHappy == 'false') {
disabledSkippy.enabled = false
println'I\'m not happy :-('
} else {
println'I\'m happy :-)'
}
}
task disabledSkippy << {
println'I\'m happy, so I jump!'
}
disabledSkippy.dependsOn skippyMood
 |
| Přeskočení tasku pomocí property enabled |
Zdrojový kód na Bitbucketu: 03_SkipTask/build.gradle
Task rules, dynamické generování tasků
Už jsem párkrát naznačoval cosi o dynamičnosti Gradle, pojďmě se tedy podívat na něco konkrétního. Co kdybychom potřebovali větší množství tasků, které dělají v podstatě to samé, akorát se to "to" liší nějakými parametry. Můžeme takovou potřebu řešit pomocí principů objektového programování, třeba. kompozicí. To může být docela otrava, hlavně správa a přetestovávání takových tasků.Co si takhle potřebné tasky nechat dynamicky vygenerovat? Právě od toho jsou tady task rules.
def environments = [
'DEV': ['url': 'http://dev:8080'],
'SIT': ['url': 'http://sit:9090'],
'UAT': ['url': 'http://uat:7001']]
tasks.addRule('Pattern: deploy<ENV>') { taskName ->
if (taskName.startsWith('deploy')) {
task(taskName) << {
def env = taskName - 'deploy'
if (environments.containsKey(env)) {
def url = environments[env].url
println"Deploying to ${env} environment, url: ${url}"
} else {
println"Unsupported environment: ${env}"
}
}
}
}
 |
| Příklad spuštění jednotlivých task rules |
Vzhledem ke své povaze jsou task rules uvedeny v samostatné sekci při výpisu tasků pomocí příkazu gradle tasks:
 |
| Výpis pravidel (rules) příkazem gradle tasks |
Zdrojový kód na Bitbucketu: 04_TaskRules/build.gradle
Asi v tom bude nějakej háček
Jedním z nejčastějších problémů u tasků, se kterým se můžeme zpočátku setkávat, je záměna konfigurace a definice tasku. Definici tasku už známe - používali jsme ji celou dobu. V rámci definice přidáváme do tasku jednotlivé akce, které jsou pak vykonány během exekutivní fáze. Jen pro připomenutí, akce můžeme do tasku přidat metodami doFirst a doLast a daleko nejčastěji se používá operátor << který je aliasem pro metodu doLast.Konfigurace tasku slouží... ehm, ke konfiguraci tasku. Podstatné je, že konfigurace je vykonána v jiné fázi buildu. A proběhne pokaždé, i když zrovna daný task nespouštíme. Task lze nakonfigurovat několika způsoby, ten "problematický" má stejnou syntaxi jako definice tasku, pouze je bez << operátoru.
task foo {
// some task configuration here
}
V následujícím výpisu task pitfall prvně "nakonfigurujeme" a následně do něj přidáme akci.task pitfall { task ->
println"Printed from task ${task.name} configuration."
}
pitfall << { task ->
println"Printed from task ${task.name} execution."
}
Když se podíváme na spuštění tasku pitfall, všimněte si, kdy proběhl "konfigurační" výpis. Ještě před začátkem spuštění tasku (tedy před vykonáním obsažených akcí).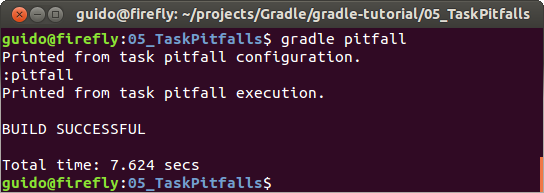 |
| "Vizualizace" konfigurační a exekuční fáze tasku |
Druhým častým problémem s tasky bývá následující chyba:
Cannot add task ':exists' as a task with that name already exists.Což znamená, že se snažíme definovat task, který už je definován někde jinde. Problém bude buď v chybné syntaxi, anebo v praxi daleko častěji, pokud pracujeme s projektem, kde používáme plugin, který task stejného jména již obsahuje. Obdobou téhož je, když si do projektu natáhneme antovské tasky (jeden z budoucích dílů tutorialu) a opět, dané jméno tasku už je použito.
Pokud řešíme druhý případ (duplicitní název/definice tasku), můžeme task explicitně předefinovat. Nemusím zdůrazňovat, že bychom měli vědět co a proč to děláme. Pokud máme buildovací skripty plně v rukou, bude tento problém indikovat chybu v designu buildu. Ovšem v případě, že se potýkáme s nějakým legacy buildem (staré Ant build soubory), může být redefinice tasku nutností.
Task lze předefinovat pomocí property overwrite:
task exists << {
println'primary task definition'
}
task exists(overwrite: true) << {
println'overwritten task definition'
}
 |
| Redefinice tasku pomocí property overwrite |
Zdrojový kód na Bitbucketu: 05_TaskPitfalls/build.gradle
Zdrojové kódy
Zdrojové kódy k dnešnímu dílu jsou k dispozici na Bitbucketu. Můžete si je tam buď probrouzdat, stáhnout jako ZIP archiv, anebo - pokud jste cool hakeři jako já :-) - naklonovat Mercurialem:
hg clone ssh://hg@bitbucket.org/sw-samuraj/gradle-tutorial
Co nás čeká příště
O tascích by se dalo povídat ještě dlouho. Ale protože jsem příznivcem hesla better is enemy of done, tasky dnešním dílem opouštíme a příště se podíváme, jak Gradle řeší Java vývoj.Tento článek byl původně publikován na serveru Zdroják.
Související články
Související externí články
- Build Script Basics (Gradle User Guide)
- More about Tasks (Gradle User Guide)
- Task (Gradle DSL Reference)































































































